On this page
Customer support quality assurance (QA) is the systematic process of evaluating interactions, chats, emails, calls, and social media DMs to ensure they meet your standards for accuracy, tone, and resolution. When you measure support quality consistently, you catch drift before it becomes a reputation problem. Right now, with AI and multi-channel support, QA isn't optional; it's how you maintain trust at scale.
Honestly? Most teams wait until complaints pile up before they look at QA. By then, the damage is done. A solid QA process catches small issues early, before they snowball into team-wide bad habits that frustrate your customers and drain your retention rates.
Quick Answer
- Measure support quality using CSAT, FCR, and QA score.
- Train QA specialists through calibration sessions and real transcript analysis.
- Scale QA by sampling 20-30% of tickets and using AI to flag grammar/tone errors.
- Use a shared inbox like Supplo to unify scoring across email, chat, WhatsApp, and social DMs.
What Is Customer Support Quality Assurance And Why Does It Matter Right Now?
Here's the deal: customer support QA is the systematic process of evaluating interactions to ensure they meet your standards for accuracy, tone, and resolution. It answers two questions: Did we solve the problem? And did we do it in a way that builds loyalty?
Legacy QA relied on random call listening, grabbing a tape, scoring it, hoping it was representative. Modern QA spans email, WhatsApp, Instagram, and live chat from a single inbox. And that's where the real shift happens. When you're measuring customer support quality assurance across every channel your customers use, you spot problems before they become patterns.
The old approach was reactive. You'd notice a dip in CSAT scores after three months and start digging. The new approach is proactive; you're catching one-off mistakes and fixing them before they spread. With AI handling routine queries and multi-channel support becoming the norm, QA is no longer optional. It's the guardrail that keeps your brand trustworthy as you scale.
How to Measure Support Quality Without Guesswork
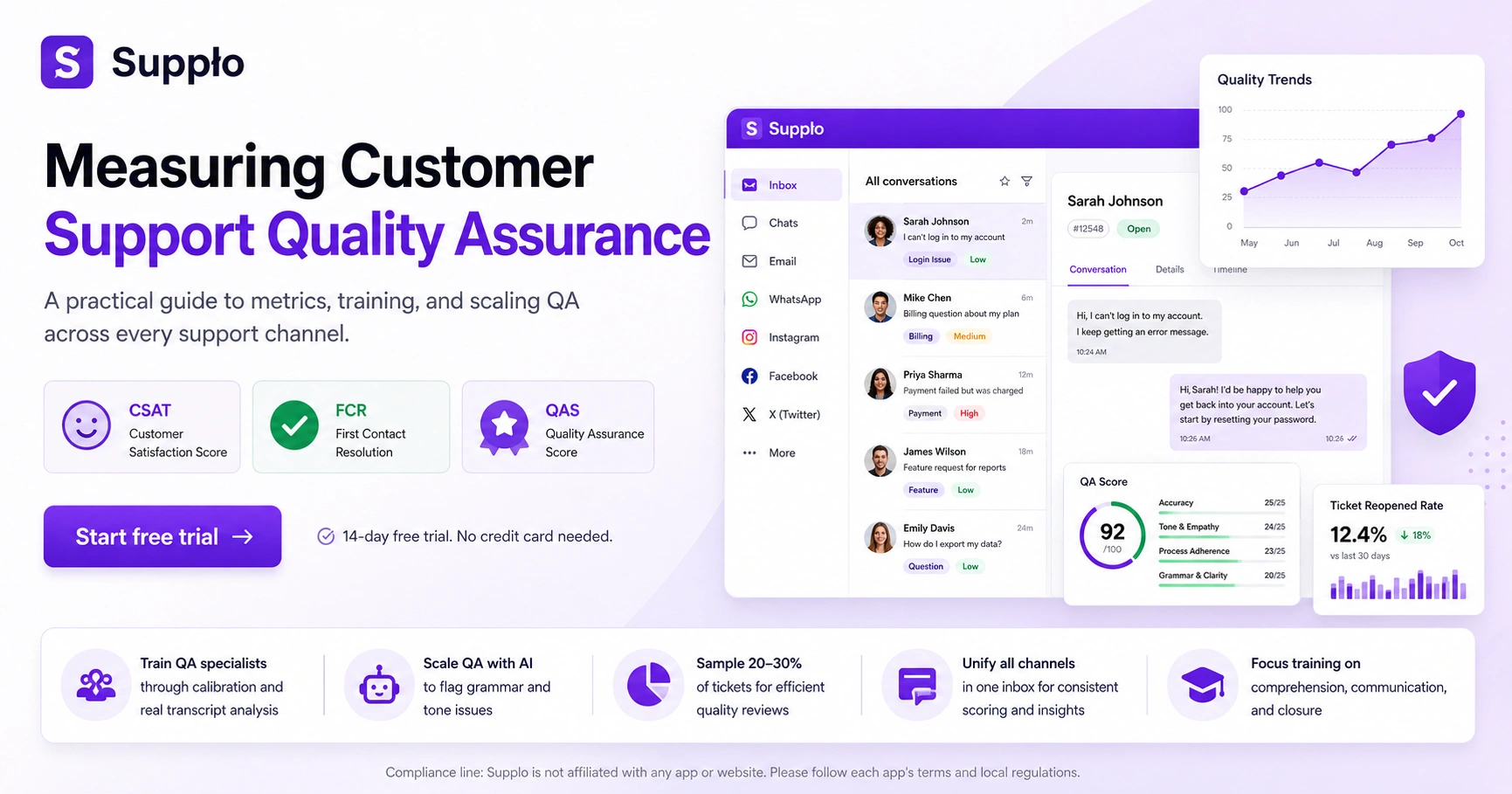
You need three foundational metrics, and I'll tell you why each one matters. Customer Satisfaction Score (CSAT) tells you how the customer felt. First Contact Resolution (FCR) tells you if they had to repeat themselves, which is the single fastest way to annoy a paying customer. Quality Assurance Score (QAS) tells you if your agent actually followed your process.
Without these three, you're flying blind. One good survey won't reveal a broken escalation flow. A high CSAT score can hide the fact that your agents are skipping critical steps. And FCR without QA context? You might think you're closing tickets fast, but you could be leaving customers frustrated.
- CSAT is transactional; send a survey after each ticket for immediate feedback.
- FCR reduces repeat contact, which is often the highest hidden cost in support.
- QAS combines objective criteria (accuracy, grammar, tone, adherence) into a single score.
- Avoid vanity metrics like "average handle time"; speed without quality destroys trust.
- Track trends weekly, not yearly; one bad quarter can surface in CSAT scores fast.
Ready to start tracking? Sign up for Supplo's free 14-day trial, no credit card needed. Set up your QA dashboard in under 10 minutes and start scoring your first 50 tickets today. → Start free trial
Key Metrics for Customer Service QA Every Team Should Track
Beyond the big three, there's an entire category of metrics that reveal hidden cracks in your support operation. Response Quality Score, grammar, empathy, and completeness indicate whether your agents sound human or like chatbots. Escalation Rate shows you whether agents are actually handling issues or just passing the buck. And Ticket Reopening Rate? That's the smoking gun for incomplete resolutions.
Here's the thing: CSAT alone can't spot process gaps. I've seen teams with 4.8 CSAT scores and 30% reopening rates. Customers were happy in the moment, until they had to contact support again the next day. These auxiliary metrics catch those blind spots.
- An escalation rate over 20% suggests your agents lack autonomy or that your knowledge base is thin.
- A ticket reopening rate above 15% often indicates that the first-contact resolution was partial or inaccurate.
- Response Quality Score can be automated with AI tools that flag grammar and tone in real time.
- Track these weekly and review in a 30-minute standup; don't let metrics sit in a dashboard unread.
Evaluating Customer Support Performance: The Human Side of the Scorecard
Let me be blunt: a scorecard is only as good as the people applying it. You can have the world's most detailed rubric, but if two QA analysts look at the same ticket and give wildly different scores, your data is meaningless. That's where calibration comes in.
Calibration means having multiple QA analysts score the same ticket blind and then comparing the results. Without it, one agent might get a 95 from one reviewer and a 72 from another. That destroys trust in the process, and rightfully so. Agents can spot inconsistent scoring from a mile away.
- Run monthly calibration sessions with 3–5 sample tickets; use a shared rubric (accuracy, tone, process adherence).
- Include both customer-facing and internal-only tickets to catch blind spots.
- Address disagreement immediately: "Why did you give a 5 on tone while I gave a 3?" Reveals assumptions.
- Document calibration decisions as a living rubric and update it quarterly as processes evolve.
Learn how a well-calibrated scorecard looks in a modern shared inbox. → What a modern QA inbox looks like
Customer Support Quality Assurance Training: Building a Program That Sticks
Here's a hot take: most QA training is boring and useless. Why? Because it relies on staged role-plays that don't reflect real interactions. If you want your QA specialists actually to improve, use real anonymized transcripts. Real messes. Real customers being impossible. Real problems.
Structure your training around three blocks: comprehension (did the agent understand the issue?), communication (did the customer feel heard?), and closure (was the issue fully resolved?). A 4-week onboarding program beats a one-day workshop every single time.
- Week 1: Shadow scoring with senior QA, score alongside, then compare.
- Week 2: Score solo with weekly audit; manager reviews every 5th ticket blind.
- Week 3: Calibration training, participate in group scoring sessions.
- Week 4: Full autonomy with random spot checks.
- Include "bad ticket" analysis: study the worst-scoring interactions to learn pattern recognition.
Training for Support QA Specialists: From New Hire to Calibration Pro
Not everyone should be a QA specialist. It takes specific skills: pattern recognition (spotting a recurring error across 50 tickets), constructive feedback delivery (marking a score is easy; coaching the agent is hard), and rubric interpretation (applying consistent standards across different channels). Don't throw people into QA without training.
Pair new specialists with a mentor for their first 100 scored tickets. That mentor should review every score and flag inconsistencies, not to punish, but to teach. The goal is consistency, not perfection.
- Teach the "feedback sandwich" for delivering scores: positive observation → growth area → encouraging close.
- Run mock calibration sessions in which specialists defend their scores to a panel, building confidence and consistency.
- Use a shared QA library of exemplar tickets (great, acceptable, poor) for quick reference.
- Assess specialists quarterly: audit 10 of their scored tickets against a master reviewer.
Improving Support Agent Performance Through QA Training Without Micromanaging
Here's the golden rule of QA: if it feels like punishment, agents will resist it. If it feels like coaching, they'll lean in. Frame QA training as a performance amplifier. "Here's what you're doing well, and here's one thing to tweak." That's the message.
Use QA scores to generate personalized coaching plans. An agent struggling with tone gets empathy exercises. One missing resolution step gets playbook drills. When you tailor the training to the specific gap, agents improve faster, sometimes 30% faster than those who only see a score.
- Pair each agent with a QA specialist for monthly 1-on-1 reviews focused on 2–3 growth areas.
- Create "mini-modules" based on common errors: e.g., a 15-minute video on handling angry customers.
- Gamify improvement: publish anonymized team scores (not individual) and celebrate weekly gains.
- Never use QA scores as the sole performance metric; combine with CSAT and FCR for a balanced view.
Using QA data for coaching, not punishment, is key. → See how Supplo's AI agent resolves up to 80% of tickets
How to Scale Support QA Processes for a Growing Team
Here's the problem with scaling QA: manual processes don't scale. When your team goes from 5 to 50 agents, you can't have your QA team reading every single ticket. You need rules, automation, and tiered review.
Start with sampling rules. Review 100% of new hires during their first 30 days. Drop it to 20% for tenured agents. But always review 100% of escalated tickets; that's where the expensive mistakes live. Then layer in automation to flag tickets with low grammar scores or suspiciously long handle times.
- Define sampling tiers: 100% of tickets from agents in their first 30 days, 50% in the first 90 days, then 20% thereafter.
- Automate flagging: "tone score below 3" or "ticket reopened within 24 hours" triggers automatic QA review.
- Use a shared QA dashboard (like Supplo's inbox) where all team members see their scoring history.
- Rotate QA specialists across channels (chat, email, social DMs) every quarter to prevent channel bias.
Efficient QA for High Volume Support: Automation, Sampling, and AI
Let's talk about high-volume support, 200+ tickets per day per agent. At that scale, you can't score every interaction. It's physically impossible. But you can be smart about what you review.
Use stratified random sampling. Pick tickets from different channels, at different times of day, and from agents with different experience levels. That gives you a representative picture without having to read everything. Then pair it with AI tools that automatically flag low-quality responses, missing greetings, grammar errors, and non-answers. Human QA specialists focus on the edge cases, not the routine stuff.
- Sample 10–15 tickets per agent per week, selected randomly with bias toward complex or escalated tickets.
- Use AI to pre-score basics: grammar, tone, greeting use, and adherence to closure; human QA specialists review only flagged tickets.
- Track QA efficiency: how many tickets does each QA specialist review per hour? Aim for 8–12.
- Supplo's AI agent can handle up to 80% of tickets automatically, letting your human team focus on the nuanced interactions that need the most QA.
Scaling Customer Support Quality Assurance Without Adding Headcount
Here's the thing most teams miss: you don't need to hire more QA specialists to scale. You need automation, better workflows, and a centralized inbox. Lean on AI to pre-screen tickets for quality flags. Then use a system that automatically assigns flagged tickets for human review.
With this hybrid approach, your existing team can handle three times the volume. No extra hires. No exploding headcount. And the best part? A flat pricing model means no per-seat costs ballooning as you grow. (Yes, that's a Supplo thing; it's baked into our DNA.)
- Use Supplo's AI agent to auto-score responses for tone and accuracy before a human sends the reply.
- Set up automated workflows: if a ticket is reopened within 4 hours, route it to QA automatically.
- Integrate your knowledge base with QA: if an agent consistently deviates from the KB article, flag it for retraining.
- Accept that 100% QA coverage is unrealistic at scale; 20–30% sampling with automated triggers catches most issues.
If your QA process feels clunky or inconsistent, Supplo's inbox unifies all channels into one thread-based view. Flag tickets for QA, auto-assign scores, and run calibration. Try it free. → Free trial
Key Takeaways
- Measure support quality using CSAT, FCR, and QA score, never just one metric alone.
- Train QA specialists through calibration sessions and real transcript analysis, not theory.
- Scale QA by sampling 20-30% of tickets and using AI to flag grammar/tone errors.
- Use a shared inbox like Supplo to unify scoring across email, chat, WhatsApp, and social DMs.
- QA training should focus on comprehension, communication, and closure.
- Automate where possible to reduce manual review workload.
- Regularly update your QA rubrics to stay aligned with evolving processes.
FAQ
What's the difference between CSAT and QA scoring?
CSAT measures how the customer *felt* after a ticket; it's subjective. QA scoring measures how well the agent followed your process; it's objective. Both matter, but they tell different stories.
How many tickets should we have per agent QA review each week?
For most teams, 8–12 per agent per week is enough to spot patterns. If an agent is new or on a performance plan, bump it to 20. For high-volume teams, use automated flags to reduce manual work.
Can AI replace QA specialists?
Not entirely; AI can flag grammar, tone, and process errors, but it can't judge empathy or creative problem-solving. Use AI to pre-screen, and let humans review the edge cases. Supplo's AI agent handles the bulk of routine queries, so your QA team can focus on quality.
How do I get buy-in from agents for a QA program?
Frame it as coaching, not punishment. Share anonymized team benchmarks and celebrate improvements. When agents see QA data helping them earn higher CSAT scores, they'll adopt it.
What metrics should I ignore in QA?
Average handle time (AHT) and first response time are operational metrics, not quality ones. Speed without quality frustrates customers. Focus on CSAT, FCR, and QA score.
How often should QA rubrics be updated?
Every quarter, or after any major process change (new channel added, new product launched). Rubrics go stale fast; stale rubrics create misaligned scores.
What do I do if QA scores are consistently low across the team?
That's a training or process problem, not an agent problem. Review your knowledge base, check if agents have the right tools, and consider whether your rubrics are realistic. If every agent fails, fix the system first.
Compliance line: Supplo is not affiliated with any app or website. Please follow each app's terms and local regulations.